
Алексей Федорчук
Этот материал посвящен ZFS — универсальной системе размещения данных, интегрирующей в себе собственно файловую систему и технологию управления дисковыми массивами и логическими томами. Первый вариант сочинялся для журнала LinuxFormat, #164-167 (декабрь 2012-февраль 2013), и ныне размещён в авторской редакции здесь и здесь. Данный же материал представляет собой обобщённую, подкорректированную и дополненную версию, не полностью совпадающую, однако, с исходными статьями.
Общее введение
Одна из главнейших задач при работе на компьютере – манипулирование данными: создание, модификация, копирование, перемещение и так далее. И тут первое – это организация их размещения. Это понятие включает в себя широкий круг частных вопросов – схемы дисковой разметки, управления дисковыми массивами и логическими томами, файловые системы и их монтирование в файловую иерархию. Они тесно связаны между собой, но традиционно решаются каждая с помощью собственного инструментария.
Однако в последние годы в Linux’е получили распространение интегрированные системы размещения данных, объединяющие в себе и файловые системы, и задачи управления массивами и томами, и даже, частично, задачи разметки дисков. Такие системы, как мы увидим из исторического обзора, существовали очень давно – со времен доисторического UNIX’а, но были они проприетарными. ZFS же, разработанная фрмой Sun для своей ОС Solaris, ныне распространяется свободно, под лицензией CDDL. Благодаря чему была портирована на FreeBSD, а в последние годы нативно поддерживается и в Linux’е.
Именно ZFS on Linux и будет героиней нашего романа, и не только в силу своих несравненных достоинств. А во-вторых, развитие проекта ZFS on Linux блестяще демонстрирует торжество инженерного разума над юридической заумью. И потому являет собой просто замечательный литературный сюжет, мимо которого не в силах пройти ни один сочинитель в жанре технологической новеллы. И начать этот сюжет надо издалека.
Дисковая разметка
Говорят, что во времена далекие, теперь почти былинные, файловых систем не было: информация на носители записывалась побитно, без всякой организации в именованные её наборы. Впрочем, такой способ записи данных применялся и много позднее – например, при резервном копировании на стриммерные ленты. Можно обходиться без файловых систем и при записи на стандартные блочные устройства – винчестеры, SSD, компакт-диски.
Однако в большинстве случаев данные на носителях блочного типа организуются в виде файлов, а файлы объединяются в файловые системы – плоские, как в древнем DOS’е, древовидные, как во всех UNIX-подобных операционках, или, так сказать, «многодревные», как в Windows. Каковые могут быть созданы непосредственно на носителе как raw-устройстве, но обычно накладываются на дисковые разделы.
До недавнего времени в Linux’е применялась разметка в MS-DOS-стиле, предполагающая возможность разбиения диска на четыре раздела, называемых первичными [primary partitions]; один из них может быть определён как расширенный раздел [extended partition], внутри которого по «матрёшечному» принципу можно создать логические разделы, максимальным числом до 63.
Разметка в MS-DOS-стиле преобладает в дистрибутивах Linux’а и по сей день. Однако всё большее распространение получает разметка в GPT-стиле. Среди её преимуществ – возможность создания на диске до 128 абсолютно равноправных (то есть не разделяющихся на физические и логические) разделов. А в случае использования винчестеров «продвинутого» формата [Advanced Format] и SSD, размер блоков которых равен 4 КБ, она обеспечивает оптимальное выравнивание границ разделов.
Исторически сложилось так, что одному разделу соответствовала одна файловая система. Соответственно, и выходить за границы несущего их устройства файловые системы не могли. И если требовалось работать более чем с одной файловой системой на одном физическом накопителе (а в UNIX-подобных ОС это почти всегда так), то был необходим тщательный расчет дискового пространства для каждой из них: ошибки в расчетах влекли весьма неприятные последствия, вплоть до необходимости переразбиения диска и переустановки ОС вообще.
Правда, дисковые разделы могут не только разделяться, но и объединяться в программные массивы или в группы томов, о которых мы сейчас и поговорим.
Массивы и логические тома
Задача объединения носителей информации особенно актуальна при использовании нескольких физических накопителей, и особенно при их добавлении в работающую систему. В элементарном исполнении это делалось просто (по крайней мере, в UNIX-подобных ОС): второй (новый) накопитель просто размечался по соответствующей для данной ОС схеме, на нем создавалась новая файловая система определенного типа, которая монтировалась в общую файловомую иерархию. Однако выход за границы существующего раздела и диска для файловой системы был по-прежнему невозможен.
Для решения задачи объединения физических носителей в единое логическое устройство и «размазывания» по ним файловых систем традиционно используется два основных способа: RAID (Redundant Array of Independent Disks – избыточный массив независимых дисков) и LVM (Logical Volume Manager – менеджер логических томов).
RAID’ы существуют трёх видов – аппаратные, квази-аппаратные (так называемые Fake RAID) и чисто программные (Soft RAID). Первые дороги и на десктопах почти не встречаются; работа вторых под Linux’ом часто проблематична, так что речь пойдёт в основном о третьих. Впрочем, с точки зрения логики это роли почти не играет.
Логически в любом из RAID’ов несколько дисков (а в Soft RAID – и дисковых разделов) могут просто слиться воедино (Linear RAID), при записи на них может осуществляться расщепление данных [stripping], что приводит к ускорению дисковых операций (RAID Level 0); на объединенных разделах можно создать различные формы избыточности, обеспечивающей восстановление данных при отказах дисков. Из таких избыточных массивов чаще всего используется полное дублирование (RAID Level 1, он же mirror) или избыточность за счет контрольной суммы (RAID Level 5). Наконец, возможно и совмещение стриппинга с дублированием.
RAID любого типа и уровня может разбиваться (и обычно разбивается) на разделы, которые уже несут на себе файловые системы. И, таким образом, позволяют размещать их на нескольких физических устройствах. Однако они не решают второй проблемы размещения данных – необходимости расчета потребного для них дискового пространства и его перераспределения при необходимости.
Этим целям служит технология LVM, объединяющая физические носители в группы логических томов, разделяемых на собственно логические тома, которые, в свою очередь, разбиваются на экстенты – объединения физических блоков дисковых устройств. Логические тома предстают перед операционной системой как обычные разделы, каждый из которых может нести свою файловую систему. При этом технология LVM даёт возможность при необходимости перераспределять физическое пространство носителей между ними посредством добавления или отнятия экстентов на лету, не только без переразметки дисков, но и без перезапуска системы.
Технология LVM может обеспечить, как и RAID Level 0, стриппинг данных между физическими томами с целью повышения быстродействия файловых операций. А в сочетании с Soft RAID позволяет и создавать массивы с полной (зеркалирование) или частичной (за счёт контрольных сумм) избыточностью, повышающей надёжность.
Таким образом, LVM выполняет оба поставленных условия: слияние дискового пространства, в том числе и вновь подключаемых накопителей, и возможность его перераспределения между существующими файловыми системами, да ещё и с бонусом в качестве повышения быстродействия. Комбинация же LVM и Soft RAID позволяет и повысить надёжность. Казалось бы, чего ещё не хватает для счастья?
А не хватает для счастья простоты: если установить LVM позволяет инсталлятор почти любого современного дистрибутива, то управление логическими томами и по сей день задача не из самых тривиальных. Да к тому же мы забыли о файловых системах, без которых ни RAID, ни LVM к использованию не пригодны. Так что на очереди к рассмотрению – они.
Файловые системы
Как известно еще с советских атеистических времен, Господь Бог, создавая человека, хотел сделать его умным, честным и партийным. Но оказалось, что даже он, при всём своём всемогуществе, не смог ему дать больше двух качеств вместе.
Аналогично и с файловыми системами: разработчики хотели бы видеть их быстрыми, надежными и простыми в обращении. Давайте посмотрим, удалось ли им превзойти Господа.
В UNIX-подобных системах требование быстродействия удовлетворяется, во-первых, оптимизированным расположением каталогов, метаданных и данных файлов на физических носителях. Но во-вторых и главных – кэшированием записи.
Думаю, каждого, кто начинал знакомство с Linux’ом во времена безраздельного господства файловой системы ext2fs, поражала быстрота выполнения всех файловых операций, обусловленная их асинхронностью – то есть кэшированием данных и метаданных. Оборотная сторона медали – отказ системы по любой причине влёк за собой тяжкие последствия, вплоть до полного ее разрушения. Но и даже когда до полной катастрофы дело не доходило, отказы (например, по питанию) вызывали за собой долгую и нудную процедуру проверки целостности файловой системы.
Были разработаны различные механизмы решения этой проблемы. Однако основным в Linux стало так называемое журналирование, когда сведения о файловых операциях записываются в специальный файл журнала до того, как эти операции будут фактически выполнены. Это дает возможность после любого сбоя «откатить» файловую систему до последнего непротиворечивого состояния. Оборотной стороной чего, как обычно, является снижение быстродействия – различное для отдельных файловых систем и видов файловых операций.
Правда, с точки зрения простоты использования ни в одну из файловых систем Linux’а бросить камень рука не подымется: создание и монтирование их никаких трудностей не сулит. Так что требование «партийности» выполняется, пожалуй, при всех соотношениях «ума» и «честности». Но эта ситуация сохраняется, пока мы не начинаем комбинировать “ум, честность и партийность” файловых систем с аналогичными качествами систем управления RAID’ами или с LVM. В результате чего получаем:
- либо быстрое и простое решение на основе RAID Level 0, не блещущее надёжностью;
- либо надёжное решение без ощутимой потери быстродействия на основе одного из RAID с избыточностью, не являющееся, однако, эталоном простоты;
- либо, наконец, относительно надёжное и потенциально быстрое решение при использовании технологии LVM – однако о простоте здесь можно забыть сразу.
Причем все эти решения – многоуровневые. И очевидно, что удлинение «цепочки» уровней в любом случае приводит к снижению надежности: чем больше в ней звеньев, тем вероятней отказ всей цепи.
И тут-то и возникает вопрос: а нельзя ли уменьшить количество уровней, сделать систему более «плоской»? И системы размещения данных, в том числе и ZFS – попытка ответа на него.
Из истории систем размещения
Не в интересах правды, а истины ради нужно заметить, что ZFS была отнюдь не первой комплексной системой размещения данных – хотя её исторические предшественницы также именовались просто файловыми системами.
Первой из таких предшественниц была, видимо, файловая система Veritas (или VxFS), разработанная фирмой Veritas Software и представленная миру в 1991 году. Она же претендует на звание первой в истории мироздания журналируемой файловой системы. Хотя, насколько мне известно, JFS – эпоним всех журналируемых ФС – в своей реализации для AIX появилась в 1990 году, так что вопрос приоритета остаётся не вполне ясным.
VxFS является основной файловой системой в HP UX, работает также во всех ныне живущих проприетарных UNIX’ах и теоретически может использоваться в Linux’е. Однако о практических примерах последнего я не слышал: VxFS является системой проприетарной и весьма дорогой.
VxFS тесно интегрирована с менеджером логических томов – VxVM. Благодаря чему в ней возможно изменение (в любую сторону) размера файловой системы «на лету», включение различных режимов использования томов – стриппинг данных, их зеркалирование, а также комбинации того и другого, создание избыточных массивов по типу RAID Level 5, изменение внутренней организации данных без остановки работы. Всё это позволяет VxFS (в сочетании с VxVM) претендовать на звание комплексной системы размещения данных.
Впрочем, не меньше к тому оснований было и у AdvFS – файловой системы, разработанной к 1993 году фирмой DEC для своего проприетарного варианта UNIX, именовавшегося сначала OSF/1, затем Digital UNIX, и завершившего свою жизнь под именем Tru64 UNIX. Судьба её была печальной. Снискав заслуженное признание на своей родной платформе DEC Alpha под управлением указанной ОС, она после покупки DEC фирмой Compaq оказалась в загоне. А после того, как Compaq, в свою очередь, был поглощён фирмой Hewlett Packard, использовавшей для своего UNIX’а на платформах HP PA и Itanium только что упомянутую VxFS, AdvFS оказалась совсем не при делах.
В результате HP сделала щедрый дар сообществу свободного софта вообще и Linux-сообществу в особенности: в середине 2008 года исходники файловой системы AdvFS были открыты под лицензией GPv2 – ради максимальной совместимости с ядром Linux. С предложением использовать их в качестве богатой технологической базы для этой ОС. Правда, оговорка, что сама HP не заинтересована в дальнейшем развитии AdvFS заставляла вспомнить народную присказку: «Возьми, небоже, что мне не гоже».
Да и предложение несколько запоздало: как мы скоро увидим, к тому времени интенсивно развивались и ZFS, и btrfs.
Однако, помимо исходников, HP предоставила также доступ ко всей документации – благодаря чему об AdvFS при желании можно узнать больше, чем о любой другой проприетарной файловой системе для UNIX-подобных операционок. Это избавляет меня от необходимости описания особенностей AdvFS. Замечу только, что среди них мы увидим все черты развитой комплексной системы размещения данных. Те самые, с которыми ознакомимся, когда дело дойдёт наконец до рассмотрения устройства ZFS. Но для начала перейдём к обзору уже её истории.
Начало истории ZFS
Разработчики ZFS поставили себе честолюбивую цель: создать систему хранения данных, которая отвечала бы всем трем критериям идеала. Разработка её проводилась в компании Sun Microsystems, командой под руководством Джеффа Бонвика и Мэттью Аренса [Matthew Ahrens]. Первоначально название ZFS рассматривалось как аббревиатура от Zettabyte File System, но быстро стало просто условным именованием. Его можно интерпретировать как последнюю точку в развитии файловых систем вообще. И в последующем мы увидим: это недалеко от истины.
Результаты работы над ZFS были представлены миру в августе 2004 года. А в 2006 году она была включена в штатный состав OS Solaris 10 (релиз 6/06). То есть, подобно своим предшественницам, она также была проприетарным продуктом. И пользователям свободных UNIX-подобных систем поначалу от ее существования было ни холодно, ни жарко. Однако период камерного существования ZFS продолжался недолго – уже в ноябре 2005 года, то есть до включения в Solaris, ее поддержка была интегрирована в открытый её вариант, OpenSolaris. Ибо она основывалась на том же ядре SunOS 5, что и коммерческий прототип.
Исходники ZFS распространяются, как и собственно OpenSolaris, под лицензией CDDL (Common Development and Distribution License). Эта лицензия, базирующаяся на Mozilla Public License (MPL), не влияет на общую лицензию проекта, в состав который включены CDDL-компоненты. И потому оказывается совместимой с большинством свободных лицензий. За исключением… какой? Правильно, GPL во всех её проявлениях.
Разумеется, ZFS была задействована в клонах openSolaris, таких, как BeleniX, SchilliX и, в первую голову, в Nexenta OS. Правда, последняя развивалась в направлении коммерческой системы хранения данных, а о числе пользователей остальных можно было только гадать.
Некоторое время ZFS была доступна пользователям Macintosh’а – в Mac OS X Leopard от осени 2007 года. Правда, ходившие перед её выходом слухи, что она будет там файловой системой по умолчанию, оказались несколько преувеличенными: поддержка ZFS оказалась опциональной и лишь в режиме «только для чтения». А в последующих версиях семейства кошачьих вообще исчезла и, видимо, уже не возродится.
Так что для широких народных масс ZFS по прежнему оставалась недоступной. Пока… пока ее не портировали под FreeBSD в 2007 году, и официально не включили её поддержку в 7-ю версию этой ОС, вышедшую в начале 2008 года. В чём, как и в дальнейшем её развитии, основная заслуга принадлежит Павлу-Якубу Давидеку [Pawel Jakub Dawidek] и Ивану Ворасу [Ivan Voras]. Правда, до недавнего времени ZFS нельзя было задействовать при установке FreeBSD средствами её штатного инсталлятора и конфигуратора sysinstall. Однако это без труда можно было осуществить в дальнейшем руками. В том числе и разместить на ZFS корень файловой иерархии.
С самого начала поддержки ZFS во FreeBSD появилась и возможность задействовать её, что называется, «искаропки», в десктоп-ориентированном клоне последней – PC-BSD. А с переходом FreeBSD, начиная с версии 9.0, на новую программу установки – BSDInstall, эта функция распространилась и на материнскую систему.
Успех ZFS во FreeBSD, где она стала если не главной файловой системой, то добилась равноправия с UFS2, послужил примером для других BSD-систем. Так, ныне ZFS поддерживается в NetBSD – эта работа была начата Оливером Голдом [Oliver Gould] летом 2007 года в рамках акции Google Summer of Code. А в 2009 году Адам Хамсик [Adam Hamsik] интегрировал её код в ядро NetBSD. Правда, насколько я понимаю, использование ZFS в этой операционке рекомендуется только в экспериментальных целях.
Наконец, одно время в списках рассылки DragonFlyBSD активно обсуждался вопрос о портировании ZFS и на эту операционку. Потом, правда, разговоры эти стихли – вероятно, в связи с активной разработкой файловой системы Hammer, обладающей во многом аналогичными возможностями. Однако, учитывая лёгкость адаптации к DragonFlyBSD любых сторонних файловых систем, можно не сомневаться, что поддержка ZFS на уровне обмена данными будет включена в неё тогда и если (или если тогда), когда (и если) это кому-то понадобится.
Таким образом, пользователям большинства BSD-систем ZFS или уже доступна как нативная, или может стать доступной в ближайшее время.
Из истории юриспруденции
А что же Linux, спросите вы меня? Как обстоит дело с поддержкой ZFS в самой массовой из свободных UNIX-подобных операционных систем нашего времени? А вот с Linux’ом все оказывается гораздо сложнее. Ибо не зря поминали мы выше лицензию CDDL. Которая сама по себе очень даже свободная, и не накладывает почти никаких ограничений на распространение защищаемых ею программ.
В частности, не запрещает CDDL и коммерческого распространения производных продуктов в виде бинарников, без открытия исходных текстов. Как известно, не накладывает такого ограничения и лицензия BSD, почему включение кода поддержки ZFS в любые BSD-системы и проходит юридически безболезненно, как мы только что видели на примере FreeBSD.
А вот с лицензией GPL обеих актуальных версий (v2 и v3) CDDL входит в диалектическое противоречие. Ибо любые продукты, производные от программ под GPL, вне зависимости от формы распространения, должны сопровождаться исходными текстами. Что делает юридически невозможным включение кода поддержки ZFS непосредственно в ядро Linux, распространяемое, как известно, на условиях GPLv2.
Кроме того, невозможность включения в ядро Linux кода поддержки ZFS объясняется тем, что GPL требует распространения всех основанных на ней продуктов под GPL же, тогда как CDDL – сохранения её для «своих» компонентов.
Правда, часть кода ZFS была открыта под GPL с тем, чтобы соответствующий патч можно было включить в загрузчик Grub. Это обеспечило возможность загрузки Open Solaris непосредственно с ZFS-раздела. Однако оказалось недостаточным для полноценной реализации этой системы, которую можно было бы распространять под данной лицензией.
Впрочем, не будучи юристом, ломать голову над лицензионными вопросами не буду, и моим читателям не советую, ибо понять это всё равно невозможно. А достаточно лишь запомнить, что всеми резонными и юридически подкованными людьми признано, что поддержки ZFS в ядре Linux быть не может.
Таким образом, сложилась абсурдная, с точки зрения здравого смысла, ситуация: два программных продукта под свободными лицензиями (обсуждать вопрос, какая из них «свободней другой», мы сейчас не будем), созданные друг для друга, как Huggies и… э-ээ… место пониже спины (дальнейшие события показали, что технических сложностей при портировании ZFS на Linux практически нет), невозможно было использовать в составе одного проекта. По крайней мере, для законопослушных граждан, чтущих… нет, не уголовный кодекс, а принципы свободного программного обеспечения.
И, разумеется, здравомыслящие люди попытались эту ситуацию разрешить. И первая такая попытка была предпринята ещё в 2006 году в рамках Google Summer of Code. Основывалась она на поддержке ZFS через FUSE (Filesystem in Userspace). Поскольку модуль FUSE работает как пользовательское приложение, необходимости во включение кода ZFS в ядро Linux нет, что снимает все юридические вопросы. Однако встают вопросы другие – производительности и устойчивости.
Проект ZFS-FUSE развивается по сей день, хотя и не очень быстрыми темпами. Правда, находясь в стадии хронической бета-версии, он до сих пор рассматривается как сугубо экспериментальный. Да и в любом случае в таком виде ZFS выполнять свои функции – быть надёжным хранилищем данных большого объёма – скорее всего, не сможет.
Так что ZFS-FUSE нельзя считать кардинальным решением вопроса с этой системой размещения данных в Linux. А на то, что в его ядро будет встроена собственная реализация ZFS, рассчитывать не приходится.
Появление героини
И тем не менее, решение этой проблемы нашлось – и решение столь же изящное, сколь и очевидное. Его предложил весной 2010 года Брайан Белендорф, некогда один из основных разработчиков web-сервера Apache. Он создал модуль поддержки ZFS, который собирается и может распространяться отдельно от ядра, сохраняя прародительскую лицензию CDDL. А поскольку последняя, как уже говорилось, является лицензией «пофайловой», этим самым обходится антагонистическое противоречие – запрет на распространение продуктов, в которых смешан код, лицензируемый под CDDL и GPL.
На базе разработки Брайана возникло сразу два проекта. Первый осуществлялся индийской компанией KQ Infotech, которой уже в сентябре 2010 года удалось выпустить работоспособный, пригодный для тестирования Linux-ядра с реализацией файловой системы ZFS. А в январе следующего, 2011, года появилась финальная его версия, доступная тогда в исходниках и в виде двоичных пакетов для Fedora 14, RHEL6, Ubuntu 10.04 и 10.10.
Однако весной того же года KQ Infotech была куплена фирмой STEC, занимающейся производством SSD-накопителей, каковых, впрочем, в наших палестинах никто не видел. И работы по дальнейшему развитию нативной поддержки ZFS были свёрнуты. Хотя исходники модуля и сопутствующих компонентов до сих пор доступны, последнее их обновление происходило более года назад. А информации о дальнейшей судьбе проекта с тех пор не появлялось.
Однако сам Брайн продолжал свою работу – вместе с сотрудниками Ливерморской национальной лаборатории, каковая, будучи в подчинении Министерства энергетики США, занимается не только вопросами ядерного оружия (эвфемизмы вроде Минсредмаша в ходу не только в бывшем Советском Союзе), но и разработкой суперкомьютеров. В результате скоро возник проект ZFS on Linux – http://zfsonlinux.org, в рамках которого модуль поддержки ZFS и сопутствующие утилиты поддержки, портированные из Solaris – так называемый SPL (Solaris Porting Layer), были доведены до ума, и к началу 2011 года стали пригодны для использования в экспериментальном режиме. А к настоящему времени, несмотря на формальное сохранение статуса release candidatе, порт ZFS on Linux можно считать готовым к практическому применению.
Правда, майнтайнеры основных дистрибутивов не торопились включать поддержку ZFS в свои системы даже в качестве дополнительных неофициальных пакетов. Подозреваю, что не столько из косности и лени, сколько из-за очередной сложности: видимо, по всё тем же лицензионным ограничениям модули zfs и spl приходится привязывать к фиксированной версии (и даже конкретной сборке) ядра Linux. Что, при регулярных, даже корректирующих, обновлениях последнего требует и их пересборки.
Тем не менее, разработчики проекта воплотили результаты своей работы в виде дополнительного (так называемого PPA) репозитория для Ubuntu. А также сочинили подробные инструкции по собственноручной сборке пакетов в форматах RPM и Deb (ссылки можно найти на странице проекта).
Достаточно подробно включение ZFS описано в Gentoo Wiki. А майнтайнеры её клона, дистрибутива Sabayon, прославившиеся своей склонностью к экспериментам, включили поддержку ZFS почти «искаропки»: соответствующие модули подгружаются при старте с LiveDVD и могут быть опробованы в «живом» режиме. Хотя штатного способа установки системы на ZFS в инсталляторе этого дистрибутива, всё из-за тех же юридических заковык, и не предусмотрено.
Дистрибутив openSUSE не сподобился попасть в список «инструктируемых» на сайте проекта. Однако нет ни малейших препятствий к использованию ZFS и в нём, о чём и пойдёт речь дальше. Хотя почти всё из сказанного применимо и к любым другим дистрибутивам – все дистроспецифические детали оговорены явным образом.
Обзор возможностей
Прежде чем погружаться в вопросы, связанные с ZFS, читатель, вероятно, хотел бы убедиться в том, что это стоит делать. То есть – ознакомиться с возможностями, которые она ему предоставляет.
Для начала – немного цифр. В отличие от всех предшествовавших файловых систем и систем размещения данных, ZFS является 128-битной. То есть теоретическое ограничение на её объём и объёмы её составляющих превышают не только реальные, но и воображаемые потребности любого пользователя. По выражению создателя ZFS, Джеффа Бонвика [Jeff Bonwick], для её заполнения данными и их хранения потребовалось бы вскипятить океан.
Так, объём пула хранения данных (zpool – максимальная единица в системе ZFS) может достигать величины 3×1023 петабайт (а один петабайт, напомню, это 1015 или 250 байт, в зависимости от системы измерения). Каждый пул может включать в себя до 264 устройств (например, дисков), а всего пулов в одной системе может быть тоже не больше 264.
Пул может быть разделён на 264 наборов данных (dataset – в этом качестве выступают, например, отдельные файловые системы), по 264 каждая. Правда, ни одна из таких файловых систем не может содержать больше 248 файлов. Зато размер любого файла ограничивается опять же значением в 264 байт.
Количество таких ограничений можно умножить. Как уже было сказано, они лежат вне пределов человеческого воображения и возможностей. И привожу я их только для того, чтобы вселить в пользователя уверенность: ни он сам, ни его внуки и правнуки в реальности не столкнутся c ограничениями на размер файловой системы или отдельного файла, как это бывало при использовании FAT или ext2fs.
Так что перейду к особенностям ZFS, наиболее интересным, по моему мнению, десктопному пользователю. Здесь в первую очередь надо отметить гибкое управление устройствами. В пул хранения данных можно объединить произвольное (в обозначенных выше пределах) число дисков и их разделов. Устройства внутри пула могут работать в режиме расщепления данных, зеркалирования или избыточности с подсчётом контрольных сумм, подобно RAID’ам уровней 0, 1 и 5, соответственно. В пул можно включать накопители, специально предназначенные для кэширования дисковых операций, что актуально при совместном использовании SSD и традиционных винчестеров.
Пул хранения становится доступным для работы сразу после его создания, без рестарта машины. В процессе работы дополнительные диски или разделы, в том числе и устройства кэширования, могут как присоединяться к пулу, так и изыматься из его состава в «горячем» режиме.
Пул хранения может быть разделён на произвольное количество иерархически организованных файловых систем. По умолчанию размер их не определяется, и растёт по мере заполнения данными. Это избавляет пользователя от необходимости расчёта места, потребного под системные журналы, домашние каталоги пользователей и другие трудно прогнозируемые вещи. С другой стороны, не запрещено при необходимости и квотирование объёма отдельных файловых систем – например, домашних каталогов отдельных излишне жадных пользователей.
Файловые системы ZFS также доступны для размещения на них данных сразу после создания, никаких специальных действий по обеспечению их монтирования не требуется. Создание файловых систем внутри пула – процесс предельно простой: разработчики стремились сделать его не сложнее создания каталогов, и это им вполне удалось. Но при этом составляющие пула остаются именно самостоятельными файловыми системами, которые могут монтироваться со своими специфическими опциями, в зависимости от назначения.
Среди других возможностей ZFS, интересных настольному пользователю, можно упомянуть:
- создание снапшотов файловой системы, позволяющих восстановить её состояние в случае ошибки;
- клонирование файловых систем;
- компрессия данных файловой системы и дедупликация (замена повторяющихся данных ссылками на «первоисточник»);
- создание нескольких копий блоков с критически важными данными и, напротив, возможность отключения проверки контрольных сумм для повышения скорости доступа к ним.
В общем, даже если не говорить об быстродействии ZFS (а оно весьма высоко, особенно в многодисковых конфигурациях), перечислять её достоинства можно очень долго. Так долго, что поневоле успеваешь задаться вопросом: а есть ли у неё недостатки?
Разумеется, есть. Хотя большая их часть – скорее особенности: например, ограничения при добавлении или удалении накопителей в пуле, или отсутствие поддежки TRIM.
По большому счёту для пользователя Linux’а у ZFS обнаруживается два кардинальных недостатка: некоторая усложнённость её использования, обусловленная юридическими факторами, и высокие требования к аппаратуре.
Первый недостаток если не ликвидирован, то сглажен трудами Брайана Белендорфа [Brian Behlendorf] со товарищи и майнтайнерами прогрессивных дистрибутивов вкупе с примкнувшими к ним независимыми разработчиками. Аппаратные же претензии ZFS мы сейчас и рассмотрим.
Аппаратные потребности
Итак, ZFS предоставляет пользователю весьма много возможностей. И потому вправе предъявлять немало претензий к аппаратной части – процессору (изобилие возможностей ZFS создает на него достаточную нагрузку), оперативной памяти и дисковой подсистеме.
Впрочем, претензии эти отнюдь не сверхъестественные. Так, процессор подойдёт любой из относительно современных, начиная, скажем, с Core 2 Duo. Минимальный объём памяти определяется в 2 ГБ, с оговоркой, что применение компрессии и дедупликации требуют 8 ГБ и более.
Сама по себе ZFS прекрасно функционирует и на одиночном диске. Однако в полном блеске показывает себя при двух и более накопителях. В многодисковых конфигурациях рекомендуется разнесение накопителей на разные контроллеры: современные SSD способны полностью загрузить все каналы SATA-III, и равномерное распределение нагрузки на пару контроллеров может увеличить быстродействие.
К «железным» претензиям добавляются и притязания программные. В первую очередь, ZFS on Linux требует 64-битной сборки этой ОС, поскольку в 32-разрядных системах действует ограничение на адресное пространство физической памяти. Кроме того, в конфигурации ядра должнв быть отключена опция CONFIG_PREEMPT. Поэтому, например, в openSUSE ZFS может использоваться с ядром kernel-default, но не kernel-desktop, каковое, вопреки названию, устанавливается по умолчанию при стандартной настольной инсталляции.
Если вас привлекли достоинства ZFS и не устрашили её «железные» аппетиты, самое время опробовать её в деле. Что потребует знакомства с некоторыми специфическими понятиями.
Терминология
Центральным понятием ZFS является пул хранения данных [zpool]. В него может объединяться несколько физических устройств хранения – дисков или дисковых разделов, причём первый вариант рекомендуется. Но не запрещено и создание пула из одного диска или его раздела.
Каждый пул состоит из одного или нескольких виртуальных устройств [vdev]. В качестве таковых могут выступать устройства без избыточности (то есть всё те же диски и/или их разделы), или устройства с избыточностью – зеркала и массивы типа RAID-Z.
Зеркальное устройство [mirror] – виртуальное устройство, хранящее на двух или более физических устройствах, но при чётном их количестве, идентичные копии данных на случай отказа диска,
RAID-Z – виртуальное устройство на нескольких устройств физических, предназначенное для хранения данных и их контрольных сумм с однократным или двойным контролем чётности. В первом случае теоретически требуется не менее двух, во втором – не менее трёх физических устройств.
Если пул образован устройствами без избыточности (просто дисками или разделами), то одно из vdev, соответствующее ему целиком, выступает в качестве корневого устройства. Пул из устройств с избыточностью может содержать более одного корневого устройства – например, два зеркала.
Пулы, образованные виртуальными устройствами, служат вместилищем для наборов данных [dataset]. Они бывают следующих видов:
- файловая система [filesystem] – набор данных, смонтированный в определённой точке и ведущий себя подобно любой другой файловой системе;
- снапшот [snalishot] – моментальный снимок текущего состояния файловой системы, доступный только для чтения;
- клон [clone] – точная копия файловой системы в момент его создания; создаётся на основе снимка, но, в отличие от него, доступен для записи;
- том [volume] – набор данных, эмулирующий физическое устройство, например, раздел подкачки.
Наборы данных пула должны носить уникальные имена такого вида:
pool_name/path/[dataset_name][@snapshot_name]
Пулы и наборы данных в именуются по правилам пространства имён ZFS, впрочем, довольно простым. Запрещёнными символами для всех являются символы подчёркивания, дефиса, двоеточия, точки и процента. Имя пула при этом обязательно должно начинаться с алфавитного символа и не совпадать с одним из зарезервированных имён – log, mirror, raidz или spare (последнее обозначает имя устройства «горячего» резерва). Все остальные имена, в соответствие с демократическими традициями пространства имён ZFS, разрешены.
А вот об именах физических устройств, включаемых в пул, следует сказать особо.
Модели именования устройств
В современном Linux’е использование для накопителей имён «верхнего уровня», имеющих вид /dev/sda, не является обязательным, а в некоторых случаях и просто нежелательно. Однако правила менеджера устройств udev позволяют определять и другие модели идентификации накопителей. В частности, штатными средствами дисковой разметки openSUSE предусмотрены варианты идентификации по:
- метке тома (/dev/disk/by-label);
- идентификатору диска (/dev/disk/by-id);
- пути к дисковому устройству (/dev/disk/by-path);
- универсальному уникальному идентификатору, Universally Unique IDentifier (/dev/disk/by-uuid).
А с полным списком вариантов идентификации блочных устройств можно ознакомиться, просмотрев имена подкаталогов в каталоге /dev/disk, их содержимое – это символические ссылки на имена «верхнего уровня».
С идентификацией по метке тома и по UUID, вероятно, знакомо большинство читателей. И к тому же в пространстве имён ZFS они не используются. А вот с идентификацией by-path и by-id нужно познакомиться поближе.
Модель именования by-path использует имена устройств, привязанные к их положению на шине PCI и включающие номер шины и канала на ней. Имя дискового устройства выглядит примерно так:
pci-0000:00:1f.2-scsi-0:0:0:0
Дисковые разделы маркируются добавлением к имени устройства суффикса part#.
Модель именования by-path идентифицирует устройства вполне однозначно, и особенно эффективна при наличии более чем одного дискового контроллера. Однако сами имена и устройств, и разделов описываются довольно сложной для восприятия последовательностью. Да и в большинстве «десктопных» ситуаций модель эта избыточна.
Модель идентификации by-id представляет имена носителей информации в форме, наиболее доступной для человеческого понимания. Они образованы из названия интерфейса, имени производителя, номера модели, серийного номера устройства и, при необходимости, номера раздела, например:
ata-SanDisk_SDSSDX120GG25_120823400863-part1
Таким образом, все компоненты имени устройства в модели by-id определяются не условиями его подключения или какими-то правилам, а задаются производителем и жестко прошиты в «железе». И потому эта модель является наиболее однозначной для именования устройств. А также, что немаловажно, строится по понятной человеку логике. Не случайно именно она принята по умолчанию в инсталляторе openSUSE.
Какую из моделей именования устройств выбрать для данного пула – зависит от его назначения и масштабов. Имена «верхнего уровня» целесообразно применять для однодисковых пулов (особенно если в машине второго диска нет и не предвидится, как обычно бывает в ноутбуках). Они же, по причине простоты и удобопонятности, рекомендуются для экспериментальных и разрабатываемых пулов. И очень не рекомендуются – во всех остальных случаях, так как зависят от условий подключения накопителей.
Этого недостатка лишена модель by-id: как пишет Брайан, при её использовании «диски можно отключить, случайно смешать и подключить опять произвольным образом – и пул будет по-прежнему корректно работать». Как недостаток её рассматривается сложность конфигурирования больших пулов с избыточностью. И потому она рекомендуется для применения в «десктопных» и «квартирных» (типа семейного сервера) условиях.
Для больших (более 10 устройств) пулов из дисков, подключённых к нескольким контроллерам, рекомендуется идентификация by-path. Однако в наших целях она громоздка и избыточна.
Наконец, ZFS on Linux предлагает и собственную модель идентификации – /dev/disk/zpool, в котором именам by-path ставятся в соответствие уникальные и осмысленные «человекочитаемые» имена, даваемые пользователем. Модель эта рекомендуется для очень больших пулов, каковых на настольной машине ожидать трудно.
Так что дальше я буду использовать имена «верхнего уровня», говоря об абстрактных или экспериментальных ситуациях, и об именах by-id, когда речь зайдёт о практических примерах применения ZFS.
Включение поддержки ZFS
Для практического использования ZFS on Linux перво-наперво необходимо обеспечить её поддержку в вашем дистрибутиве – ибо по причинам, описанным в предыдущей статье, сама собой она не поддержится ни в одном Linux’е.
Как это сделать, зависит от дистрибутива. В Сети можно найти подробные инструкции для Ubuntu и Gentoo, которые легко распространяются на клоны обеих систем. Не столько инструкции, сколько руководства к самостоятельному действию имеются на сайте проекта ZFS on Linux для абстрактных RPM- и Deb-based дистрибутивов. Я же расскажу о том, как это делается в openSUSE релизов 12.1 и 12.2.
Как вы наверняка догадались, ZFS не поддерживается в openSUSE ни «искаропки», ни в официальных репозиториях. Но зато в репозиториях неофициальных, так называемых «домашних», пакеты её поддержки представлены аж в двух экземплярах: в munix9 и в ghaskins. Точные их адреса легко найти через систему OBS (Open Builging System) по ключевому слову zfs.
Какому из репозиториев отдать предпочтение – вопрос спорный. Первые свои опыты с ZFS on Linux я проводил, основываясь на пакетах из munix9. И они прошли без всяких осложнений, хотя и велись в сугубо экспериментальном режиме. Однако к моменту понимания, что эта система для меня – «всерьёз и надолго», последняя тогда версия zfs имелась только в репозитории ghaskins. Однако его использование требует некоторых дополнительных манипуляций.
Кроме того, в репозитории ghaskins на данный момент имеются пакеты только для openSUSE релизов 12.1 и 12.2. Репозиторий же munix9 охватывает все актуальные ныне версии SLE и openSUSE. включая Tumbleweed и Factory.
Различаются репозитории и набором пакетов. В ghaskins, кроме «рабочих» модулей zfs и spl для ядра default, можно видеть массу отладочных их сборок:
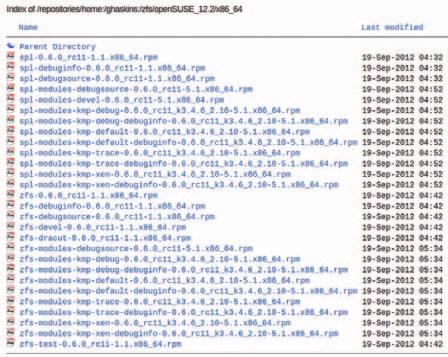
В репозитории munix9 с этим существенно скромнее – имеются модули только для ядра default и для xen:

Так что окончательный выбор я предоставляю читателю. Но на какой бы репозиторий он ни пал, его следует подключить. И сделать это можно любым из трёх способов. Первый – с помощью zypper’а:
# zypper ar -f [URL] [Name]
Второй способ – через модуль Репозитории… центра управления YaST2 посредством кнопки Добавить:

выбора пункта Указать URL:
и ввода необходимых значений в поля Имя репозитория и URL (рис. 5):
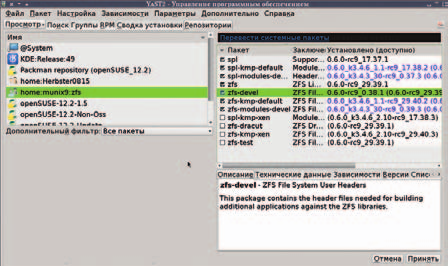
Наконец, третий способ, для самых ленивых – отыскать пакеты zfs, spl и сопутствующие через OBS и прибегнуть к «установке в один клик». В этом случае подключение репозиториев будет совмещено с установкой пакетов. В первых двух же вариантах после подключения репозитория надо будет установить (с помощью zypper’а или модуля управления пакетами YaST’а) следующее (пример дан для репозитория munix9, но из ghaskins потребуются те же компоненты):
Возможно, не вредным окажется и пакет zfs-test. А вот zfs-dracut, предназначенный для создания initrd с поддержкой ZFS, несмотря на его потенциальную нужность, установить не удастся: требуемый для него пакет dracut в openSUSE пока не поддерживается.
Следует учесть, что при использовании ядра kernel-desktop (а скорее всего, так оно и есть) пакет zfs-kmp-default потянет за собой и соответствующее ядро kernel-default. Пункт загрузки которого будет внесён в меню GRUB, но не будет отмечен как умолчальный – этим надо озаботиться самому.
И, наконец, при использовании пакетов из ghaskins потребуется, скорее всего, сделать в каталогах /etc/init.d/rc3.d и /etc/init.d/rc5.d символические ссылки на файл /etc/init.d/zfs. Иначе файловые системы ZFS, к созданию которых мы приближаемся, не будут автоматически монтироваться при старте и размонтироваться при останове системы.
При использовании репозитория munix9 эти действия будут нечувствительно выполнены в ходе установки пакетов.
Вот теперь можно приступать к применению ZFS в мирных практических целях.
Создаём простой пул
Освоив ранее основные понятия, мы научились понимать ZFS. Для обратной же задачи – чтобы ZFS понимала нас – нужно ознакомиться с её командами. Главные из них – две: zpool для создания и управления пулами, и zfs для создания и управления наборами данных. Немного, правда? Хотя каждая из этих команд включает множество субкоманд, с которыми мы со временем разберёмся.
Очевидно, что работу с ZFS следует начинать с создания пула хранения. Начнём с этого и мы. В простейшем случае однодисковой конфигурации это делается так:
# zpool create tank dev_name
Здесь create – субкоманда очевидного назначня, tank – имя создаваемого пула (оно обычно даётся в примерах, но на самом деле может быть любым – с учётом ограничений ZFS), а dev_name – имя устройства, включаемого в пул. Каковое может строиться по любой из описанных ранее моделей. И, чтобы не повторяться, напомню: все команды по манипуляции с пулами и наборами данных в них выполняются от лица администратора.
В случае, если в состав пула включается один диск, и второго не предвидится, можно использовать имя устройства верхнего уровня – например, sda для цельного устройства (обратим внимание, что путь к файлу устройства указывать не нужно). Однако реально такая ситуация маловероятна: загрузка с ZFS проблематична, так что как минимум потребуется раздел с традиционной файловой системой под /boot (и/или под корень файловой иерархии), так что команда примет вид:
# zpool create mypool sda2
Однако если можно ожидать в дальнейшем подсоединения новых накопителей и их включения в существующий пул, то лучше воспользоваться именем по модели by-id, например:
# zpool create mypool ata-ata-ST3500410AS_5VM0BVYR-part2
Очевидно, что в случае однодискового пула ни о какой избыточности говорить не приходится. Однако уже при двух дисках возможны варианты. Первый – создание пула без избыточности:
# zpool create mypool dev_name1 dev_name2
где dev_name1 и dev_name1 – имена устройств в принятой модели именования.
В приведённом случае будет создано нечто вроде RAID’а нулевого уровня, с расщеплением [stripping] данных на оба устройства. Каковыми могут быть как дисковые разделы, так и диски целиком. Причём, в отличие от RAID0, диски (или разделы) не обязаны быть одинакового размера:
# zpool create mypool sdd sdf
После чего никаких сообщений не последует. No news – good news, говорят англичане; в данном случае это означает, что пул был благополучно создан. В чём можно немедленно убедиться двумя способами. Во-первых, в корневом каталоге появляется точка его монтирования /mypool. А во-вторых, этой цели послужит субкоманда status:
# zpool status mypool
которая выведет нечто вроде этого:
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
sdd ONLINE 0 0 0
sdf ONLINE 0 0 0
errors: No known data errors
А с помощью субкоманды list можно узнать объём новообразованного пула:
# zpool list mypool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mypool 18,9G 93K 18,9G 0% 1.00x ONLINE -
Легко видеть, что он равен сумме объёмов обеих флэшек, если «маркетинговые» гигабайты пересчитать в «настоящие».
К слову сказать, если дать субкоманду list без указания аргумента – имени пула, то она выведет информацию о всех пулах, задействованных в системе. В моём случае это выглядит так:
# zpool list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mypool 18,9G 93K 18,9G 0% 1.00x ONLINE -
tank 199G 20,8G 178G 10% 1.00x ONLINE -
Обращаю внимание, что даже чисто информационные субкоманды вроде list и status требуют прав администратора.
Разумеется, два пула в одной, да ещё и настольной, машине – излишняя роскошь. Так что пул, созданный в экспериментальных целях, подлежит уничтожению, что делается с помощью субкоманды destroy:
# zpool destroy mypool
После чего он пропадёт из списка пулов. А что можно сделать с пулом до его уничтожения, увидим со временем.
«Избыточные» пулы
Избавившись от ставшего ненужным пула, рассмотрим второй вариант – создание пула с зеркальным устройством. Создаём его из двух накопителей одинакового объёма:
# zpool create -f mypool mirror sdf sdg
Проверка показывает, что итоговый пул, как и следовало ожидать, равен объёму одного накопителя:
# zpool list mypool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mypool 3,72G 91,5K 3,72G 0% 1.00x ONLINE -
При различии объёмов больший диск будет «обрезан» до объёма меньшего.
Полное зеркалирование любыми, по моему мнению, в настольных условиях – роскошь непозволительная: банальные бэкапы данных проще и надёжнее. Тем не менее, не исключаю, что некоторая избыточность на уровне проверки контрольных сумм может оказаться не лишней, да и не столь накладна. Так что давайте посмотрим и на третий вариант пула из более чем одного устройства – RAID-Z.
Теоретически виртуальное устройство с одинарным контролем чётности, как уже говорилось, можно создать при наличии двух устройств физических. Однако практически это оказывается накладно, особенно если устройства не одинакового размера. Поэтому задействуем под него три накопителя:
# zpool create mypool raidz sdd sdf sdg
что даст нам следующую картину:
# zpool list mypool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mypool 11,1G 205K 11,1G 0% 1.00x ONLINE -
Впрочем, как мне кажется, в настольных условиях не стоит выделки и эта овчинка.
Пул кэшируемый
И, наконец, последний вариант организации пула из более чем одного устройства – создание пула с кэшированием. Для чего создаём из двух устройств простой пул без избыточности и подсоединяем к нему устройство для кэша:
# zpool create mypool sdd sdf cache sdg
Очевидно, что устройство для кэширования не должно входить в пул любого рода – ни в простой, ни в избыточный. Что мы и видим в выводе субкоманды list:
# zpool list mypool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mypool 18,9G 82K 18,9G 0% 1.00x ONLINE -
где никаких следов его обнаружить не удаётся. Если же появляются сомнения, а подключилось ли оно на самом деле, обращаемся к субкоманде status, которая покажет беспочвенность наших опасений.
Как я уже говорил в обзоре возможностей ZFS, подключение устройства кэширования имеет смысл при наличии большого традиционного винчестера (или винчестеров) и относительно небольшого SSD, которое и играет роль дискового кэша.
О некоторых опциях команды zpool
Команда zpool поддерживает ещё множество субкоманд, предназначенных для экспорта и импорта пула, добавления к нему устройств и изъятия оных, и так далее. Но сейчас я расскажу о некоторых опциях, которые могут оказаться необходимыми при создании пула.
Одна из важный опций – -f: она предписывает принудительное выполнение данной операции и требуется, например, при создании пула из неразмеченных устройств.
Полезной может оказаться опция -n. Она определяет тестовый режим выполнения определённой субкоманды, то есть выводит результат, например, субкоманды zpool create без фактического создания пула. И. соответственно, сообщает об ошибках, если таковые имеются.
Интересна также опция -m mountpoint. Как уже говорилось, при создании пула по умолчанию в корне файловой иерархии создаётся каталог /pool_name, который в дальнейшем будет точкой монтирования файловых систем ZFS. Возможно, что это окажется не самым лучшим местом для их размещения, и, как мы увидим в дальнейшем, это несложно будет изменить. Но можно задать каталог для пула сразу – например, /home/data: это и будет значением опции -m. Никто не запрещает определить в качестве такового и какой-либо из существующих каталогов, если он пуст, иначе автоматическое монтирование файловых систем пула в него окажется невозможным.
Наконец, нынче важное значение приобретает опция ashift=#, значением которой является размер блока файловой системы в виде степеней двойки. По умолчанию при создании пула размер блока определяется автоматически, и до некоторого времени это было оптимально. Однако затем, с одной стороны, появились диски так называемого Advanced Format, с другой – получили распространение SSD-накопители. И в тех, и в других размер блока равен 4 КБ, хотя в целях совместимости по-прежнему эмулируется блок в 512 байт. В этих условиях автоматика ZFS может работать некорректно, что приводит к падению производительности пула.
Для предотвращения означенного безобразия и была придумана опция ashift. Значение её по умолчанию – 0, что соответствует автоматическому определению размера блока. Прочие же возможные значения лежат в диапазоне от 9 для блока в 512 байт (29 = 512) до 16 для 64-килобайтного блока (216 = 65536). В интересующем нас случае четырёхкилобайтного блока оно составляет 12 (212 = 4096). Именно последнее значение и следует указать явным образом при создании пула из винчестеров AF или SSD-накопителей.
Создание файловых систем
Пулы хранения представляют собой вместилища для наборов данных, для манипуляции которыми предназначена вторая из главнейших команд – zfs. Самыми важными наборами данных являются файловые системы, к рассмотрению которых мы и переходим.
Для создания файловых систем предназначена субкоманда create команды zfs, которая требует единственного аргумента – имени создаваемой ФС и обычно не нуждается ни в каких опциях:
# zfs create pool_name/fs_name
Внутри пула можно создавать сколь угодно сложную иерархию файловых систем. Единственное условие – родительская файловая система для системы более глубокого уровня вложенности должна быть создана заблаговременно. Ниже я покажу это на конкретном примере создания файловых систем внутри каталога /home – наиболее оправданное место для размещения наборов данных ZFS.
Начну я немножечко издалека. При стандартной установке openSUSE не обойтись без создания учетной записи обычного пользователя, и, следовательно, в каталоге /home будет присутствовать по крайней мере один подкаталог – /home/username.
Смонтировать же файловую систему ZFS в непустой каталог невозможно, и, значит, мы не можем сразу прибегнуть к опции -m для определения «постоянной прописки» создаваемого пула.
Поэтому для начала делаем для пула «прописку» во временной точке – пусть это будет традиционный /tank:
# zpool create -o ashift=12 tank ata-SanDisk_SDSSDX120GG25_120823400863-part3 ata-SanDisk_SDSSDX120GG25_120823402786-part3
Теперь создаём файловую систему для будущего домашнего каталога:
# zfs create tank/home
А внутри же неё – необходимые дочерние ветви, как то:
# zfs create tank/home/alv
которая потом заменит мой домашний каталог – в нём я не держу ничего, кроме конфигурационных файлов;
# zfs create tank/home/proj
это файловая система для моих текущих проектов, и так далее.
Как и было обещано разработчиками ZFS, процедура ничуть не сложнее, чем создание обычных каталогов. Благодаря этому файловые системы можно легко создавать по мере надобности, для решения какой-либо частной задачи. И столь же легко уничтожать их, когда задача эта выполнена. Что делается таким образом:
# zfs destroy pool_name/fs_name
Использовать субкоманду destroy следует аккуратно: никакого запроса на подтверждение при этом не будет. Правда, и уничтожить файловую систему, занятую в каком-либо текущем процессе, можно только с указанием опции -f, а файловую систему, содержащую системы дочерние, не получится убить и таким образом.
Ни в какой специальной операции монтирования новообразованные файловые системы не нуждаются – оно происходит автоматически в момент их создания, о чём свидетельствует следующая команда:
$ mount | grep tank
tank/home on /tank/home type zfs (rw,atime,xattr)
tank/home/alv on /tank/home/alv type zfs (rw,atime,xattr)
tank/home/proj on /tank/home/proj type zfs (rw,atime,xattr)
...
Для обеспечения монтирования файловых систем ZFS при рестарте машины не требуется и никаких записей в файле /etc/fstab: это также происходит само собой, совершенно нечувствительно для пользователя. Правда, если для файловой системы ZFS определить свойство mountpoint=legacy, то с ней можно управляться и традиционным способом.
Как и для обычного каталога, объём каждой файловой системы ничем не лимитирован, и в момент создания для любой из них потенциально доступно всё пространство пула, которое равномерно уменьшается по мере разрастания файловых систем. На данный момент в моей системе это выглядит так.
Казалось бы, для тех же целей можно ограничиться обычными каталогами. Однако в наборах данных ZFS мы имеем дело с полноценными файловыми системами, для которых могут быть установлены индивидуальные свойства, аналогичные опциям монтирования файловых систем традиционных. Чем мы сейчас и займёмся.
Файловые системы: устанавливаем свойства
При создании файловая система ZFS получает по умолчанию определённый набор свойств, во многом сходный с атрибутами традиционных файловых систем, определяемыми опциями их монтирования. Полный их список можно получить командой
# zfs get all fs_name
Свойств этих очень много, однако далеко не все они представляют для нас интерес. Важно только помнить, что любое из свойств каждой файловой системы можно поменять с помощью субкоманды set и её параметра вида свойство=значение. Причём изменение свойств для материнской системы рекурсивно распространяется на все дочерние. Однако для любой последней свойства можно изменить в индивидуальном порядке. Что я сейчас и проиллюстрирую на примерах.
Так, абсолютно лишним представляется свойство atime, то есть обновление времени последнего доступа к файлам. Оно, во-первых, снижает быстродействие, с другой – способствует износу SSD-накопителей (правда, нынче и то, и другое чисто символичны). Так что отключаем это свойство для всех файловых систем:
# zfs set atime=off tank/home
Аналогичным образом расправляемся и со свойством xattr:
# zfs set xattr=off tank/home
А вот дальше можно заняться и индивидуализацией. Как я уже говорил, в момент создания файловые системы ZFS «безразмерны». Если это не подходит, для них можно установить квоты. Однако я этого делать не буду – в моём случае это приводит к потере половины смысла ZFS. А вот зарезервировать место для критически важных каталогов, дабы его не отъела, скажем, мультимедиа, известная своей прожорливостью, будет не лишним. И потому я для файловых систем tank/home/proj и tank/home/alvустанавливаю свойство reservation. Для файловой системы проектов оно будет максимальным:
# zfs set reservation=10G tank/home/proj
Для остальных ограничусь более скромным гигабайтом резерва.
Далее, поскольку данные в файловой системе tank/home/proj для меня действительно важны, и шутить с ними я склонен даже гораздо меньше, чем с дамами, предпринимаю дополнительные меры по их сохранности путём удвоения числа копий (по умолчанию оно равно 1):
# zfs set copies=2 tank/home/proj
А для данных не столь важных – тех, что часто проще скачать заново, нежели отыскать на локальной машине, можно выполнить и обратную операцию – отказаться от подсчёта контрольных сумм:
# zfs set checksum=off tank/home/media
Для файловых систем, содержащих хорошо сжимаемые данные (например, для моего домашнего каталога, где лежат одни dot-файлы), можно включить компрессию:
# zfs set compression=on tank/home/alv
Я этого не делал: экономия места получается грошовая, а нагрузка на процессор и расход памяти, как говорят, очень приличные. Однако это свойство целесообразно включать в системах с огромными логами, если выделить под них файловую систему в пуле ZFS.
При желании для некоторых файловых систем (например, того же домашнего каталога) можно отключить такие свойства, как exec, setuid, devices – легко догадаться, что результат будет аналогичен указанию опций монтирования noexec, nosuid, nodev для традиционных файловых файловых систем. И, разумеется, для файловых систем, изменение которых нежелательно, можно придать свойство readonly.
Все необходимые свойства файловых систем желательно установить до их наполнения контентом, ибо многие из них (например, компрессия) обратной силы не имеют.
О перемонтировании
После создания файловых систем и задания всех необходимых их свойств наступает психологический момент для перемонтирования их по месту «постоянной прописки» – то есть в каталог /home. Что потребует некоторых подготовительных действий.
Поскольку предполагается, что все новообразованные файловые системы должны быть полностью доступны обычному пользователю (то есть мне, любимому), перво-наперво следует изменить атрибуты из принадлежности – ведь создавались они от имени администратора и принадлежат юзеру по имени root. Для чего даю команду:
# chown -R alv:users /tank/home/*
Теперь нужно скопировать конфиги из каталога /home/alv в /tank/home/alv:
# cp -Rp /home/alv/.* /tank/home/alv/
не забыв про опцию -p для сохранения атрибутов.
Все предыдущие операции можно было выполнять, получив права администратора с помощью команды su (или, при желании, sudo). Причём где угодно – в текстовом виртуальном терминале или в терминальном окне Иксового сеанса (например, в konsole KDE). Теперь же потребуется переавторизоваться в «голой» консоли.
Монтирование файловых систем ZFS в каталог с любым содержимым невозможно, так что требуется очистить каталог /home от следов прежней жизнедеятельности пользователя таким образом:
# rm -Rf /home/alv
При хоть одном активном пользовательском процессе в ответ на это последует сообщение об ошибке. Так что, возможно, перед этим придётся убить все реликтовые процессы, запущенные в Иксах от имени пользователя. Сначала выявляем их командой
# ps aux | grep alv
обращая внимание на идентификаторы процессов (PID). А затем последовательно мочим их в сортире:
# kill -9 ####
Выполнив все указанные действия, определяем для набора данных tank/home свойство mountpoint, что и осуществит перемонтирование:
# zfs set mountpoint=/home tank/home
Теперь остаётся только с помощью команды ls убедиться, что в /home появились новые подкаталоги с нужными атрибутами:
drwxr-xr-x 26 alv users 48 Sep 23 14:27 alv/
drwxr-xr-x 18 alv users 18 Sep 22 02:28 proj/
...
А команда
# mount | grep /home
покажет нам новые точки монтирования файловых систем:
tank/home on /home type zfs (rw,noatime,noxattr)
tank/home/alv on /home/alv type zfs (rw,noatime,noxattr)
tank/home/proj on /home/proj type zfs (rw,noatime,noxattr)
...
Как я уже говорил выше, при использовании пакетов из репозитория munix9 на этом дело с подготовкой файловых систем ZFS к практической работе можно считать законченным: при перезагрузке машины все они будут благополучно смонтированы в автоматическом режиме. Пакеты же из ghaskins потребуют ещё одного деяния – создания в каталогах /etc/init.d/rc3.d и /etc/init.d/rc5.d символических ссылок на файл /etc/init.d/zfs.
Подключение пула ZFS, созданного в другой системе
Здесь речь пойдёт о том, как подключить к некоей Linux-системе (конкретно, Ubuntu) пул ZFS, ранее созданный в другой системе — теоретически это могут быть Solaris, FreeBSD или более иной дистрибутив Linux, для которого предусмотрена поддержка ZFS on Linux. Но практически я опробовал только последний вариант, о чём и расскажу.
Перво-наперво нужно перезагрузиться в ту систему, в которой создавался пул (в моём случае это была openSUSE), и экспортировать его командой:
# zpool export data
где data — имя пула с точкой монтирования /home/data.
Следующий шаг — вернуться в Ubuntu и создать в ней аналогичную точку монтирования для пула ZFS — в моём случае таким образом:
$ sudo mkdir /home/data
Дать ей атрибуты принадлежности обычному пользователю:
$ sudo chown -R alv:alv /home/data
И импортировать созданный в openSUSE пул ZFS:
$ sudo zpool import -f data
Не забыв об опции -f, предписывающей принудительной выполнение импорта. Без неё ответом на эту команду будет сообщение об ошибке.
Теперь в каталоге /home/data можно видеть те же самые файловые системы ZFS, которые были созданы в родителькой для пула системе, вместе со всеми размещёнными в них данными. С которыми можно начинать работать.
Сказанное справедливо, если идентификаторы пользователя в обеих системах совпадают — в моём случае это именно так. Однако в случае общем это совсем не обязательно — и тогда надо озаботиться каким-либо способом обеспечения совместного доступа к ним из разных систем. Например, созданием специальной группы с правами чтения, записи и исполнения для её членов, и включением в неё соответствующих пользователей. Впрочем, к ZFS, о которой мы сейчас разговариваем, это не относится.
Опечатка:
Впрочим, с точки зрения логики это роли почти не играет.
> Впрочем
Chinaski, спасибо, поправил.